
A Prototype of Automated Web Archiving, Emulation and Server Preservation
Web Archiving Automation: Beyond Crawling
Automation has been one of the most requested features for Webrecorder. Users want to keep Webrecorder’s high fidelity capture and replay capabilities, but make it less tedious to ensure full capture of larger sites. The traditional approach to automating web archiving is crawling, automatically visiting page after page until some condition is met. But successful crawling still requires careful user oversight and trial-and-error testing. Scope the crawler too narrowly, and it’ll miss key pages; scope the crawler too broadly and it’s overwhelmed with too much data, like capturing all of Wikipedia, or stuck in a ‘crawler trap’, visiting endless generated pages. And this is before we add Javascript and different browsers into the mix.
For many complex web sites, an automated approach will always be necessary, and we are currently exploring how to bring automatation in a user-friendly way to Webrecorder. We will have more details in the next few months, so stay tuned!
In the meantime, we also wanted to find out if another approach was possible, especially if a site is a clearly defined, bounded web object.
What if a blog, a digital publication or a web platform with clear definition, could be captured automatically with a single click?
Web Archiving and Emulation, Continued
Almost three years ago, in September, 2015, we began exploring what it might mean to combine web archives with emulation, to fully preserve the original experience of browsing a website, with a fixed version of a web browser. That original project was soon released as http://oldweb.today/, which provided old emulated browsers running in Docker containers, connected to existing web archives. A web browser is a critical part of accessing the web, live or archived, and archiving a preservable copy of the the browser itself is key to maintaining the full fidelity of a particular site. For example, an archive of GeoCities looks pretty different in a contemporary version of Chrome versus Netscape Navigator.
With Webrecorder, we can now capture modern high-fidelity web content and dynamic client-side Javascript. But thanks to the prevalence and popularity of open source container technologies, and the strong support for Linux by two of the three modern browser vendors, we can now also preserve modern versions of Chrome and Firefox as soon as they are released by placing them in Docker containers. The growth of Docker, along with the emergence of the Open Container Initiative (OCI), has generally given more credence to the use of containers as preservable objects. (The original version of oldweb.today, using an obsolete version of Docker, is currently in need of an upgrade, but still operates unchanged almost 3 years later)
In late 2016, we have integrated emulated browsers into Webrecorder, supporting several versions of modern Firefox and Chrome, with support for Flash (and even Java applets).
We now have the web browser (the client), the web archive (the network data transferred to the client), but what about the final component of any website, the web server? But what if the server, like the client (browser), could be preserved in a similar way?
Web Server Preservation and Digital Publishing
The web server is usually outside the scope of web archiving, since archivists don’t generally have access to the web server, and there may be a multitude of servers across different sites spread throughout the world. In the general case, server preservation may not be realistic.
Of course there are exceptions. What if a user is trying to preserve a particular platform at full fidelity, and the server is available? What if the server is under the users control, or if it provides a full export of the data and the software is freely available?
To get the highest fidelity, preserving the server can accurately reproduce the functionality of a single site, without having to manually crawl each link. For certain types of dynamic server web content, for example a script that generates a random number or a search page, no amount of web crawling can capture the site at full fidelity, but archiving the server side software may be trivial, if access is provided.
Thus, we wanted to explore if it would be possible to add server preservation, along with browser preservation and traditional network based web archiving, to create an automated high-fidelity web preservation prototype. To start it made sense to focus on a particular use case: a commonly used platform.
Scalar Platform
Scalar, a digital publishing platform created by the Alliance for Networked Visual Culture (ANVC) proved to be a perfect platform to test this approach. Scalar is fully open source and includes an optional exporter tool, which allows content hosted on one Scalar instance to be migrated to another Scalar instance. This export/import tool makes this type of preservation possible, and inspired the creation of this prototype.
Introducing the Scalar Auto Archiving Prototype
Several Webrecorder users have asked us about Scalar, and it is also a platform used by several authors, including at least two currently publishing with Stanford University Press (SUP). When SUP invited us for a digital preservation workshop, we decided Scalar would be a good use case to examine further. Originally created for the digital preservation workshop at SUP in May, and further reviewed by the Scalar development team, we are now excited to announce and fully open source this project.
The prototype is available at: https://scalar.webrecorder.net/
The code is available at https://github.com/webrecorder/autoscalar
Here’s a video of the system in action, creating an archive of When Melodies Gather (original), published by Stanford University Press.
This process was used to create When Melodies Gather (archived version) and SUP have been very happy with the results.
Here’s a screenshot of this piece with an embedded emulated browser:
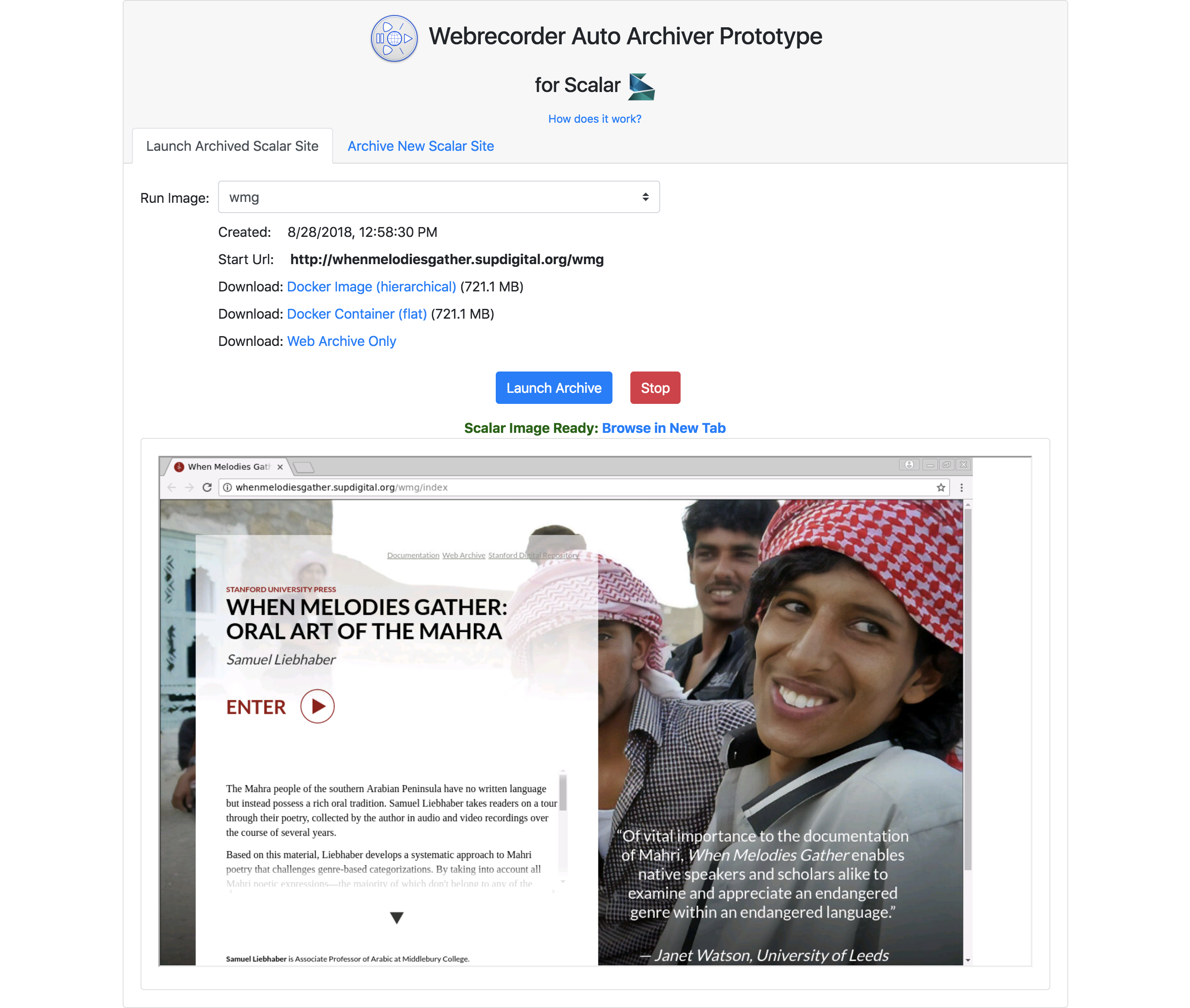
The prototype is designed to create a reproducible, preservable copy of any Scalar site, including all embedded content. This archive or preservation copy includes the Scalar software, the data (mysql database), a web archive of embedded content, and a fixed web browser that can be used to view the site.
The site consists of two modes: one for archiving a new Scalar image, and one for loading an existing Scalar image.
How it works – Archiving Scalar
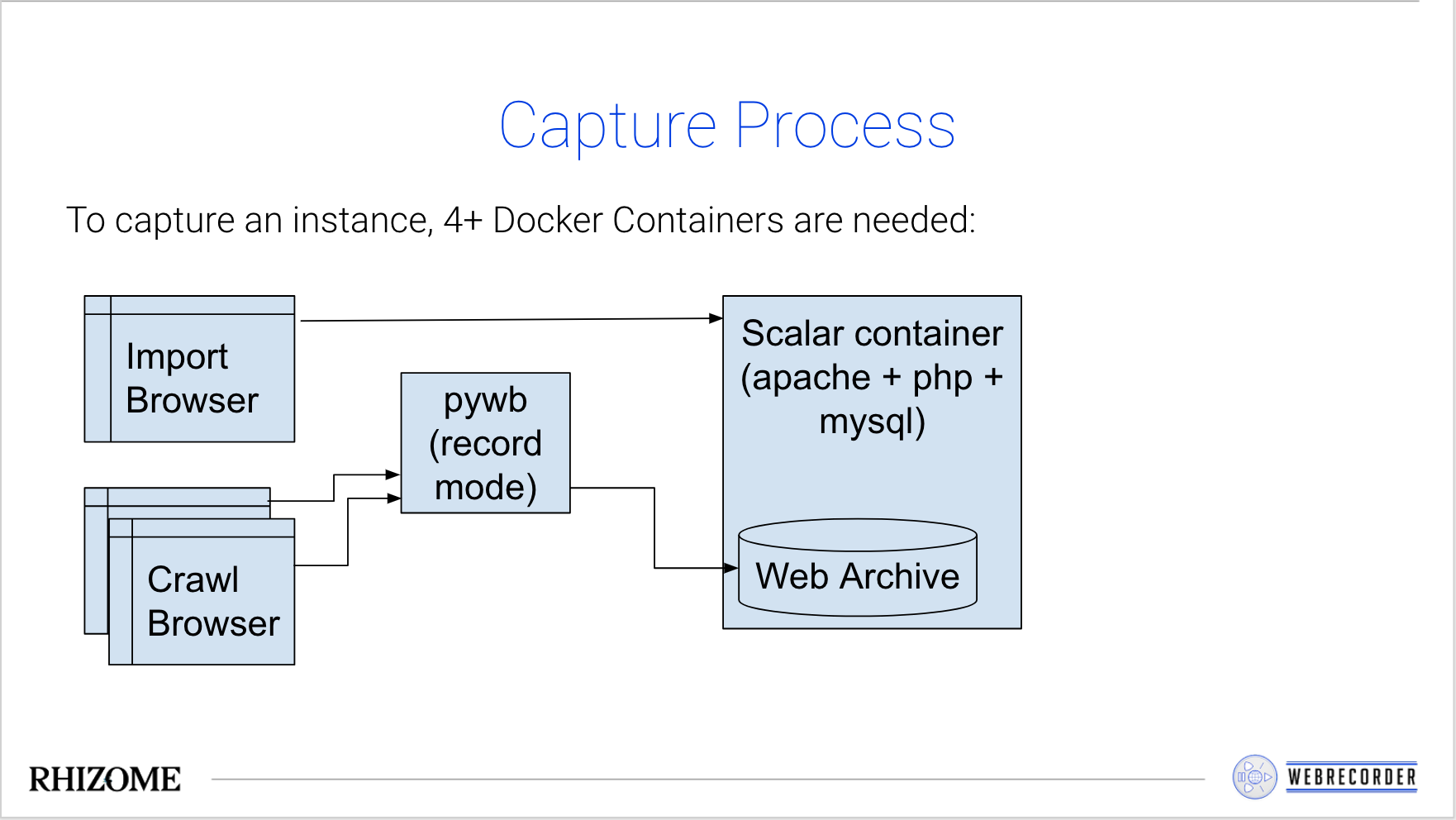
After a user enters a Scalar project home page and clicks Archive!, the system does roughly the following:
- The url is checked to be a valid Scalar site.
- A new empty Scalar Docker container is launched.
- Scalar Importer and API is used to export data from an existing Scalar project into the container.
- Other APIs are used to retrieve additional information, such as Table of Contents into the new container.
- A list of known media is obtained via the API, and queued for simple crawling (without browser).
- A list of pages with embedded media from external sites is obtained, queued for browser-based crawling.
- Up to 4 browsers are launched to load each url queued for external crawling.
- WARCs from the automated crawling are moved to the Scalar container.
- A new image containing the imported Scalar copy + web archive data is created.
To browse a Scalar site from the Launch Archived Scalar Site tab, simply select it from a drop down and click Launch Archive!.
This launches a new emulated instance for Scalar, pywb (Python Web Archive Toolkit) and a browser, and provides the user with a remote browser connected to this archived version. The archive can also be browsed in the native browser, by clicking Browse in new tab
Caveats
As this is a prototype, there are certain things that may not function, but the process generally works for most Scalar sites. One known issue is that the custom script and custom style elements in Scalar are not currently captured as they are not available in the import/export api.
At this time, the archiving process on the hosted version is password protected on https://scalar.webrecorder.net/ as this can be resource intensive. Please contact us if you’d like to try it on a self hosted version.
Developers are encouraged to try running their own instance locally (No password is set by default in the open source version)
High-Fidelity Web Archiving + Software Preservation Architecture
The end result of this system is to demonstrate the possibility of combining web archives, automation and server preservation.
The system combines web archives and preserved software, to provide the additive benefits of both. A Scalar project may have hundreds or thousands of links, but it is not necessary to collect all of them as the Scalar software and data itself becomes part of the archived Scalar image. However, Scalar sites may embed content from other sources, YouTube, Vimeo, Soundcloud, etc. and these are the pages that are automatically run through a browser based web archiving process, and written to WARCs. At this time, the prototype does not automatically visit any other links, but could be extended to perform a ‘one-hop’ crawl of all outbound non-Scalar links.
When replaying an archived Scalar image, the replay system (a customized version of pywb) provides custom routing, seamlessly combining the traditional web archive and the Scalar instance.
For example, when browser loads a url that falls in the scope of Scalar, the request is routed to the Scalar software. For any other url, it is retrieved from the web archive. This seamless combination of web server preservation/emulation and web archive replay provides new opportunities for digital publishing, where entire platforms like Scalar can be archived at once, and capturing any supporting material as a web archive.
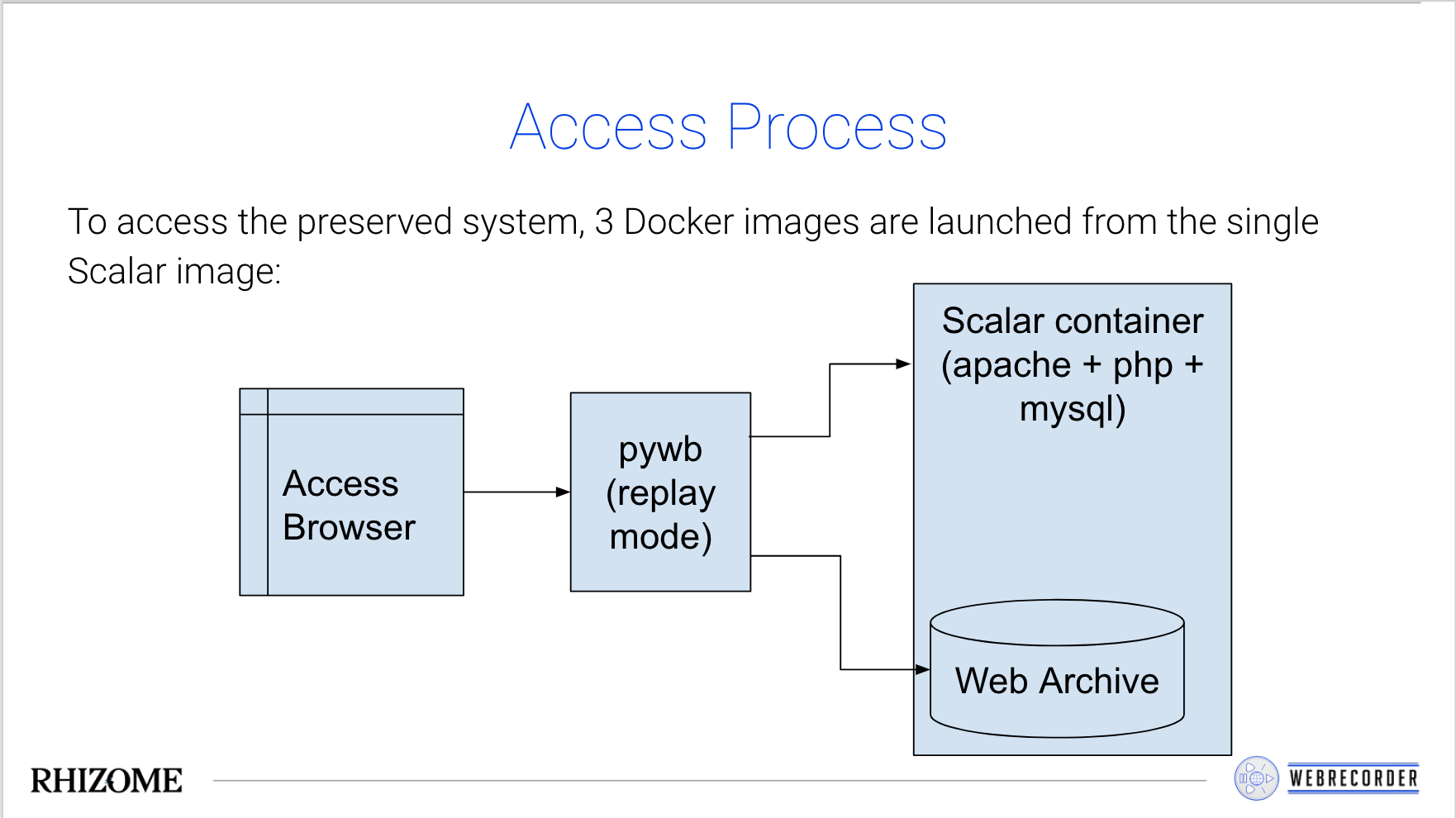
The above diagrams are from a preserntation slide deck which was presented earlier this year.
Emulation, Containers and Other Work
The server container and browser can each be thought of as a type of emulation. While not strictly running a cpu-based emulator, the browser software is fully emulated in the container, and the Scalar server software (Apache, Mysql, Php) are also fully emulated in the container.
The containers provide a kind of ‘lightweight emulator’ for the software. Of course, this is not to say that preservation is fully ‘solved’. The preservation of the container infrastructure is still required, but the threat is much less immediate, and the problem becomes more general. Instead of having to create custom tools to preserve any particular Scalar site (or any particular hosting platform), preservation effort can focus on more common digital preservation issues, such as how to preserve Docker container.
Thus, if software can be successfully containerized, the preservation of the software can be reduced to a common platform.
We wanted to mention a few other efforts that we’ve been in touch with are exploring the areas of containerization and preservation.
-
The ReproZip project provides a way for creating a container (as well as VM or other serialization) by ‘recording’ or tracing the software that is running on a machine. They have recently received a grant to explore integration of ReproZip with Webrecorder. Their use case focus on data journalism, server side data-heavy applications often published along with web sites. The prototype outlined here could be expanded to work with any Docker container following a specific spec, including those created by ReproZip. Any server side application that can run in a Docker container, could be plugged in to this system.
-
The Digits Project is also exploring the use of containerization for digital publishing. We have shared this prototype with them as an example of how containers could be used with digital publishing to ensure preservation. For example, a digital platform could be created entirely within a container, and run through the preservation system automatically, removing the need for an import/export tool and ensuring ‘archiveability’ along the way.
Feedback
If you have any questions or comments about this prototype, don’t hesitate to comment here, on github, or by writing to us at support [at] webrecorder.io